人工智能实验实战——从YOLO目标检测到Qwen3.5小模型对话
前言
今天一口气完成了人工智能课程的四项深度学习实验,涵盖目标检测、情感分析、图像生成、大语言模型对话四大方向。实验室配备 RTX 4060 8GB 显卡,全部实验均在 GPU 下完成,训练速度相当可观。下面逐一分享。
实验10:YOLOv8 目标检测
YOLO(You Only Look Once)将目标检测视为单次回归问题,从整张图像直接预测边界框与类别概率,速度快、效果好。
单图推理
使用预训练 YOLOv8n(nano 版,仅 3.2M 参数)对教室场景图片进行检测,分别测试了三组 conf 阈值:
conf 阈值对比实验
| conf 阈值 | 检测目标数 | 分析 |
|---|---|---|
| 0.1 | 27 个 | 检测出更多目标(chair, keyboard 等),但可能包含低置信度误检 |
| 0.25(默认) | 16 个 | 10 persons, 4 tvs, 2 laptops,较准确的平衡点 |
| 0.5 | 15 个 | 过滤掉一个低置信度目标,精确率提升但漏检增加 |
结论:conf=0.25 是日常使用的最佳平衡点,安防场景可降为 0.1 优先召回率,自动驾驶应提升至 0.5+ 优先精确率。
自定义训练
基于 yolov8n.pt 预训练权重,在 coco8 数据集上训练 5 个 epoch:
训练配置
- 输入尺寸:320×320
- Batch size:2
- 设备:NVIDIA RTX 4060
- 最终 mAP50:0.608
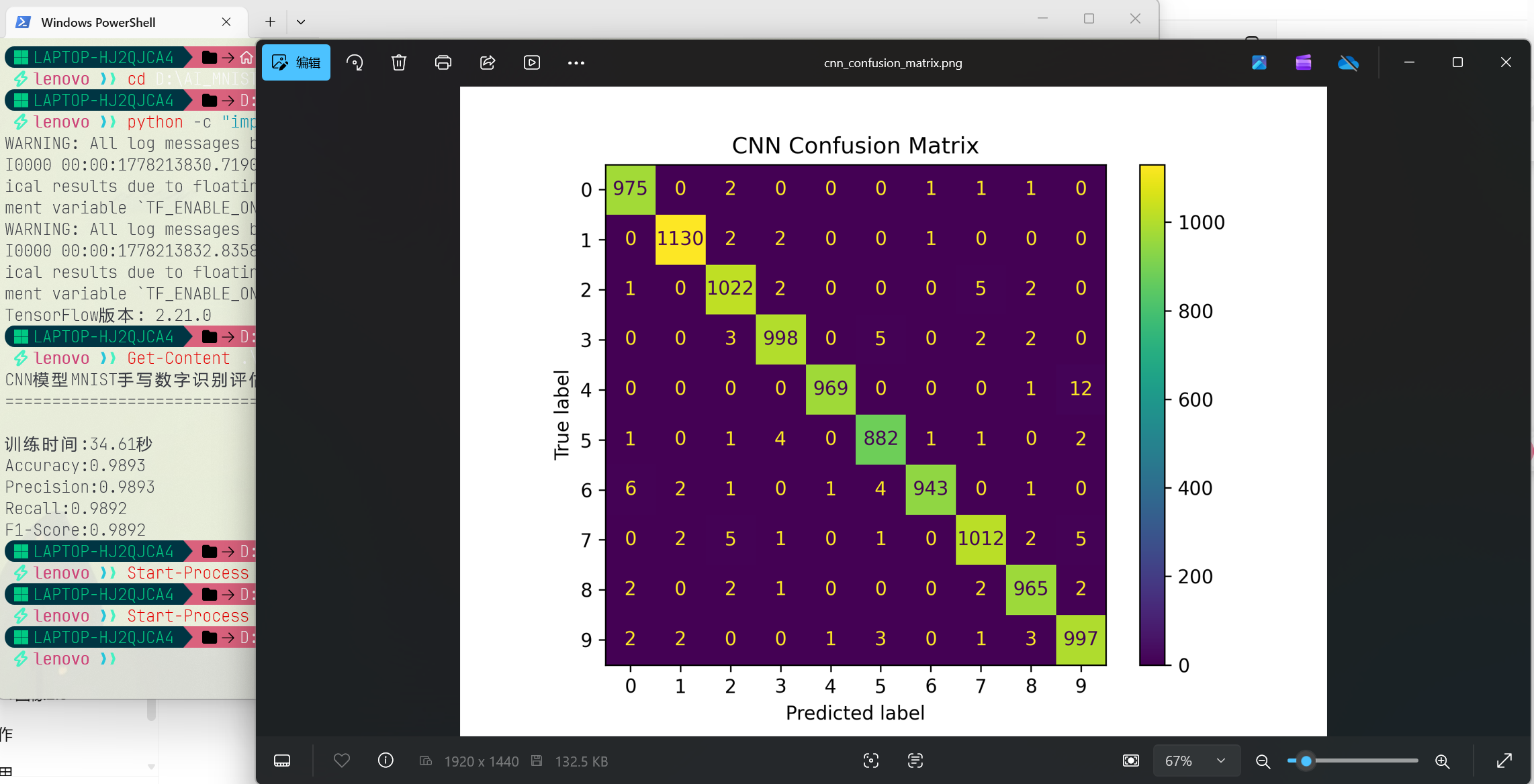
实验11:LSTM 情感分析
使用 IMDB 影评数据集(50,000 条英文评论)训练 LSTM 二分类器,判断评论情感正/负。
模型架构
Embedding(20000→128) → LSTM(128) → Linear(128→2)使用 pack_padded_sequence 让 LSTM 忽略 PAD 填充位置,取最后时刻隐状态作为句子表示。
训练结果
3轮训练效果
| Epoch | Train Loss | Train Acc | Test Loss | Test Acc |
|---|---|---|---|---|
| 1 | 0.6449 | 66.70% | 0.6762 | 56.60% |
| 2 | 0.5637 | 75.40% | 0.6488 | 61.28% |
| 3 | 0.3755 | 85.22% | 0.6122 | 68.17% |
测试准确率 67.87%,训练准确率 85.22%,存在约 17% 的过拟合。仅用了 4000 条训练数据 + 3 个 epoch,提升空间很大。
推理测试
- this movie was fantastic → Positive (P=0.561) ✅
- boring and too long → Positive (P=0.589) ❌ 预测错误
小模型碰到强烈负面词 (“boring”, “not recommend”) 仍可能翻车,需要更多训练。
实验13:GAN 生成手写数字
GAN(生成对抗网络)由生成器 G 和判别器 D 组成,G 从噪声生成图像,D 判断真/假,两者对抗训练使 G 学会生成逼真样本。
网络结构(MLP 版本)
生成器 G:z(64) → Linear(256) → ReLU → Linear(784) → Tanh → (28×28)
判别器 D:(28×28) → Linear(256) → LeakyReLU(0.2) → Linear(1) → Sigmoid
100 轮训练后生成效果
在 GAN 训练中,单看损失值并不可靠,生成图像的清晰度与多样性才是关键指标。以下是 16 张随机生成的数字:

16张生成数字(4×4网格)
大部分数字轮廓清晰、形态可辨,说明 G 已从 64 维噪声学到了合理的手写数字分布。个别边缘模糊、少数数字形态介于两类之间。
💡 改用 DCGAN(卷积 + 转置卷积)替代 MLP,可显著提升清晰度和多样性。
GAN 训练小技巧:标签平滑(真标签从 1 改为 0.9)、为 D 输入加高斯噪声、降低 D 学习率让 G 跟上。
实验22:Qwen3.5-0.8B 小模型对话
阿里开源的 Qwen3.5-0.8B,仅 0.75B 参数,本地 RTX 4060 即可运行,显存占用约 1.6GB。
下载与加载
使用 hf-mirror.com 镜像下载(国内比 HuggingFace 快很多),升级 transformers 至最新版以支持 qwen3_5 架构。加载完成后仅 0.75B 参数。
加载代码
1 | from transformers import AutoModelForCausalLM, AutoTokenizer |
功能测试
单轮对话 —— “什么是线性回归?”
线性回归是一种通过最小二乘法,利用一组已知自变量和对应的因变量数据,建立变量间线性关系的数学模型。
System 角色设定 —— 幽默 AI 讲师
正则化就像给模型加个”防作弊滤镜”,它通过让模型”偷懒”来防止过拟合。
多轮对话 —— 人工智能课程主题
第一轮:建议从线性回归、决策树、SVM 入门
第二轮(记住了上下文):CNN 与普通神经网络的区别在于局部卷积和全连接
Temperature 对比
| Temperature | 输出风格 |
|——————-|————-|
| 0(确定性) | 简洁精确:”通过不断调整参数以最小化损失函数的优化算法” |
| 0.9(随机) | 更丰富:”通过随机初始化参数,沿着优化函数曲面的负梯度方向不断调整” |
实验总结
今天的四组实验覆盖了 AI 领域三个核心方向:计算机视觉(YOLO + GAN)、自然语言处理(LSTM 情感分析)、大语言模型(Qwen3.5)。RTX 4060 虽然只有 8GB 显存,跑小模型已经绰绰有余,0.8B 的 Qwen3.5 回答质量也超出预期。
关键收获
掌握了 YOLO 的 conf/IoU 调参策略
理解了 LSTM 门控机制与 pack_padded_sequence 的作用
体验了 GAN 对抗训练的震荡与不稳定
跑通了本地小模型的完整对话流程(单轮/多轮/system/temperature/few-shot)
参考
- Ultralytics YOLO 官方文档:https://docs.ultralytics.com/zh/
- Stanford IMDB 数据集:https://ai.stanford.edu/~amaas/data/sentiment/
- Qwen3.5 模型:https://huggingface.co/Qwen/Qwen3.5-0.8B
- 动手学深度学习:https://zh.d2l.ai/