MNIST手写数字识别实战:逻辑回归、SVM与CNN对比
MNIST 是机器学习领域最经典的数据集之一,被称为”Hello World”级别的入门任务。本文将通过实战,使用三种不同的模型——逻辑回归、SVM 和 CNN——来完成手写数字识别,并从准确率、训练效率、泛化能力等多个维度进行对比分析。
实验环境
本实验使用 Python 语言,选用两个主流框架:
- scikit-learn(v1.8.0):用于构建逻辑回归模型和 SVM 模型。scikit-learn 是 Python 最流行的机器学习库之一,提供了简单高效的分类、回归、聚类等算法实现。
- TensorFlow/Keras(v2.21.0):用于构建 CNN 卷积神经网络模型。Keras 作为 TensorFlow 的高级 API,用几行代码就能搭建复杂的神经网络。
数据准备
MNIST 数据集包含 70000 张 28×28 像素的手写数字灰度图片,涵盖 0~9 共 10 个类别。实验中将前 60000 张作为训练集,后 10000 张作为测试集。
对于逻辑回归和 SVM 模型,每张图片被展开为 784 维特征向量;对于 CNN 模型,保留原始的 28×28×1 灰度图像格式。所有像素值归一化到 0~1 范围。
模型一:逻辑回归
逻辑回归虽然名字带”回归”,实际上是一种经典的线性分类算法。本实验使用 scikit-learn 的 LogisticRegression,参数设置:
max_iter=100:最大迭代次数solver='lbfgs':优化器
核心训练代码
1 | from sklearn.linear_model import LogisticRegression |
训练耗时约 8.50 秒。
模型二:支持向量机(SVM)
支持向量机通过寻找最大化类别间隔的超平面来进行分类。使用 LinearSVC 构建线性 SVM:
核心训练代码
1 | from sklearn.svm import LinearSVC |
训练耗时约 38.50 秒,明显比逻辑回归慢。
模型三:卷积神经网络(CNN)
CNN 更适合图像任务,因为它能通过卷积层提取边缘、笔画、形状等局部特征。使用 Keras Sequential 模型:
核心训练代码
1 | from tensorflow.keras.models import Sequential |
训练耗时约 34.61 秒。
模型评估与对比
在 MNIST 测试集(10000 张图片)上,使用 Accuracy、Precision、Recall 和 F1-Score 四个指标进行评估:
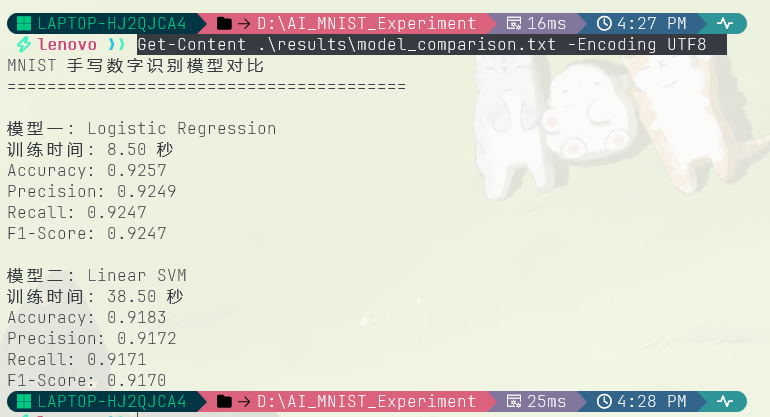
| 模型 | Accuracy | 训练时间 |
|---|---|---|
| 逻辑回归 | 8.50s | |
| SVM | 38.50s | |
| CNN | 34.61s |
CNN 的评估结果如下:

三个模型在测试集上都达到了 91% 以上的准确率,说明 MNIST 是一个相对成熟的数据集。但 CNN 的各项指标接近 0.99,明显优于两个传统模型。
混淆矩阵分析
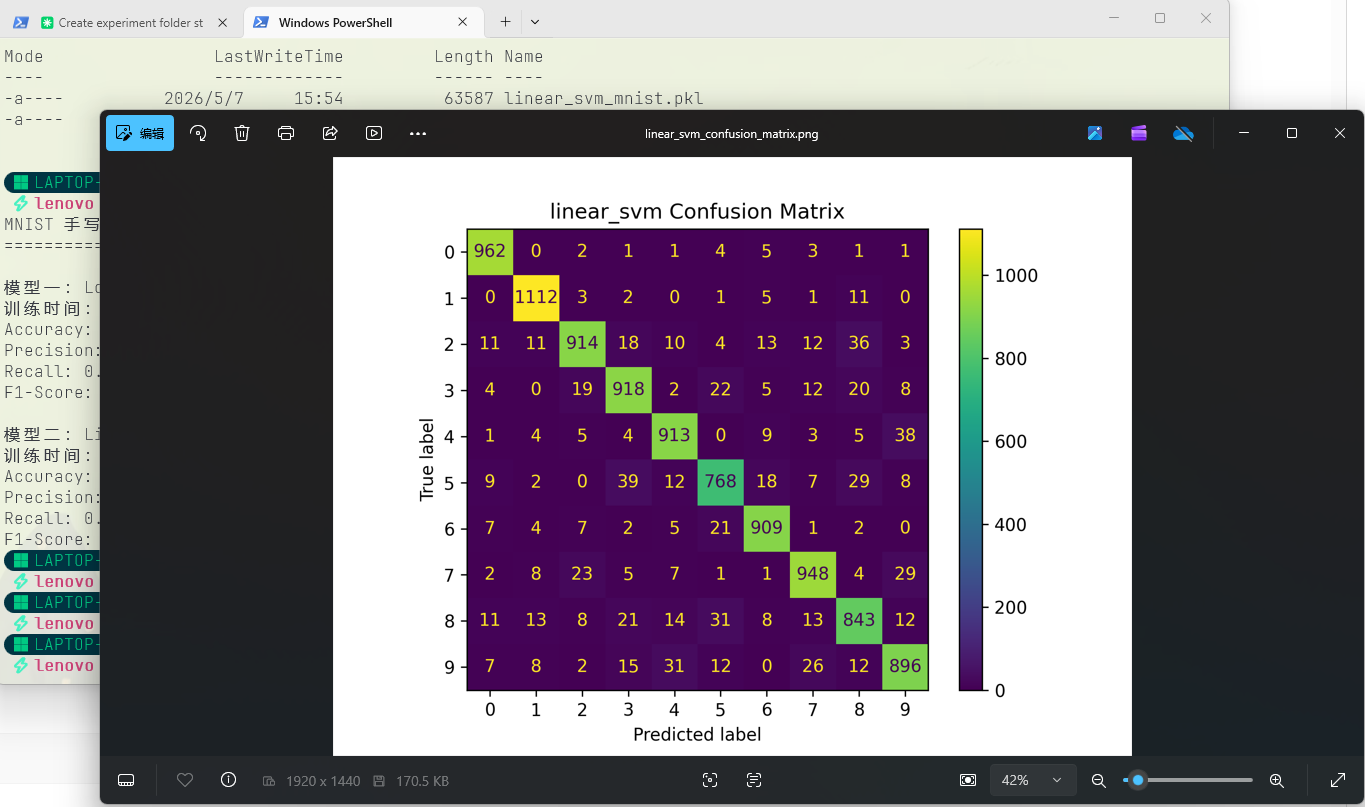
混淆矩阵能直观展示模型在每个数字类别上的分类表现,对角线越亮说明识别越准确。
逻辑回归混淆矩阵:
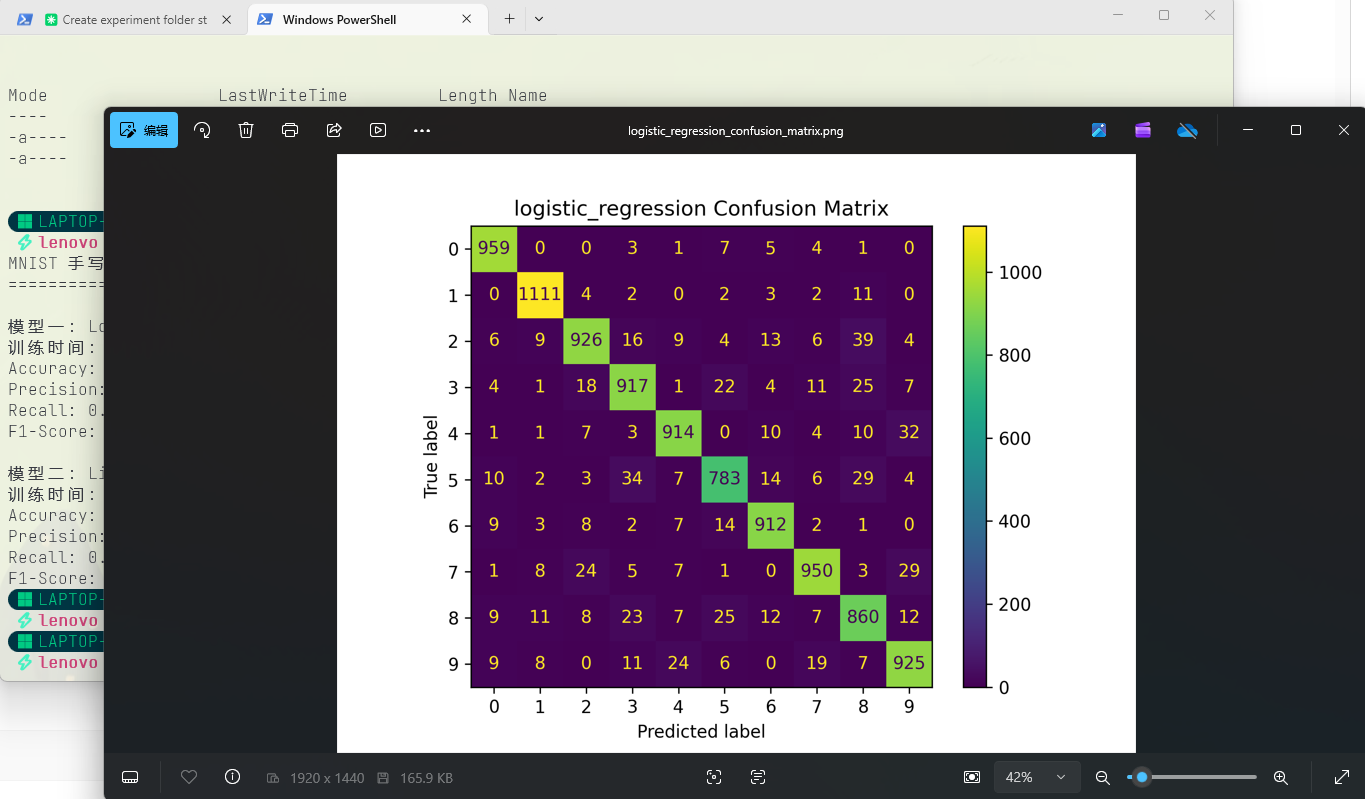
SVM混淆矩阵:
CNN混淆矩阵:
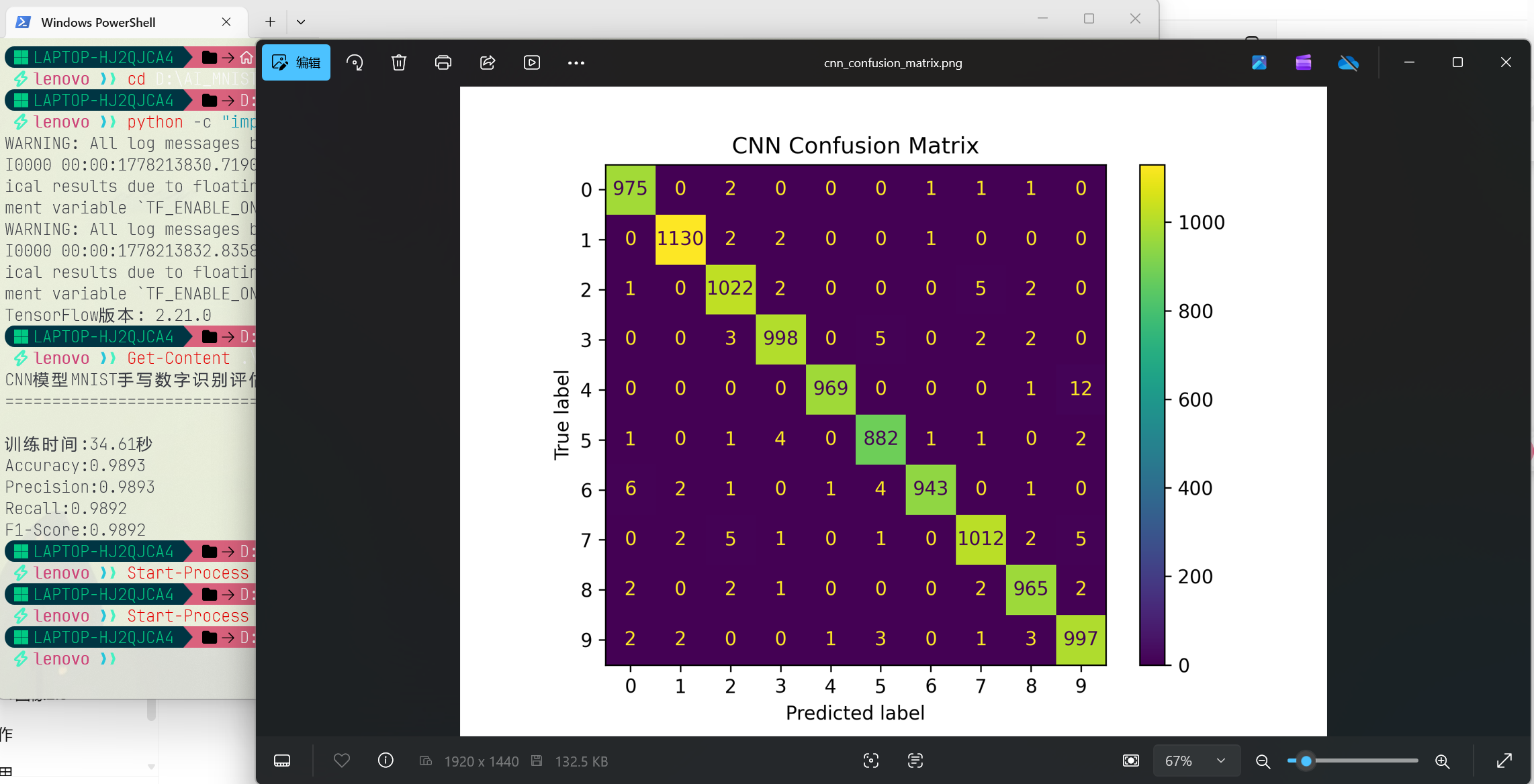
从混淆矩阵可以看出,三个模型的大部分预测都集中在对角线上。逻辑回归和 SVM 在数字 4/9、5/6、7/3 等形态相似的数字之间仍存在一定的误判。而 CNN 的混淆矩阵对角线更加集中,误分类数量明显更少。
自制手写数字测试
标准测试集表现好 ≠ 实际效果好。为了检验模型的真实泛化能力,我用画图工具手写了 0~9 共 10 张数字图片:
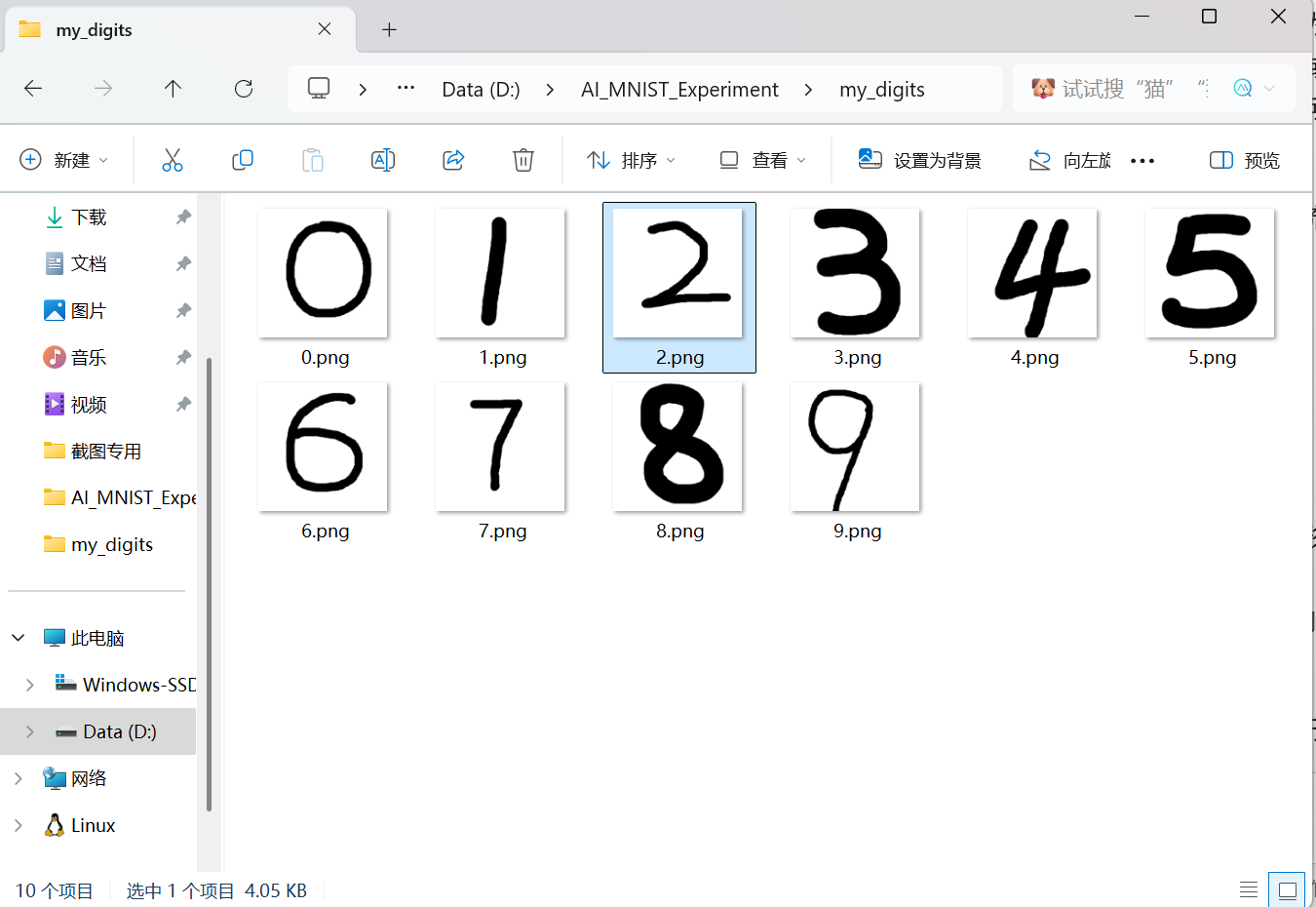
图片预处理
自制图片不能直接输入模型——它们是白底黑字的大画布,而 MNIST 是 28×28 的黑底白字灰度图。我设计了一套预处理流程:
- 读取图片并转为灰度图
- 自动寻找数字笔画区域,裁剪多余空白
- 保持比例缩放到 20×20 以内
- 居中放入 28×28 白色画布
- 反色处理,使白底黑字接近 MNIST 的黑底白字
- 像素值归一化到 0~1
核心预处理代码:
核心预处理代码
1 | def preprocess_image(image_path): |
预测结果
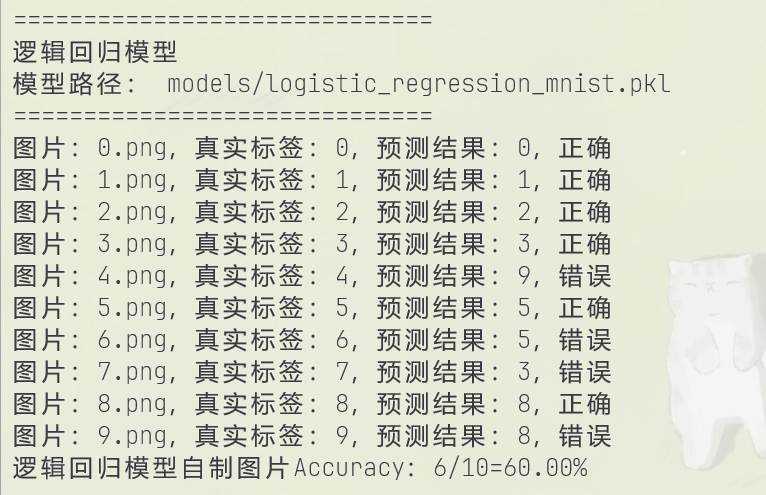
逻辑回归预测结果(6/10 = 60%):
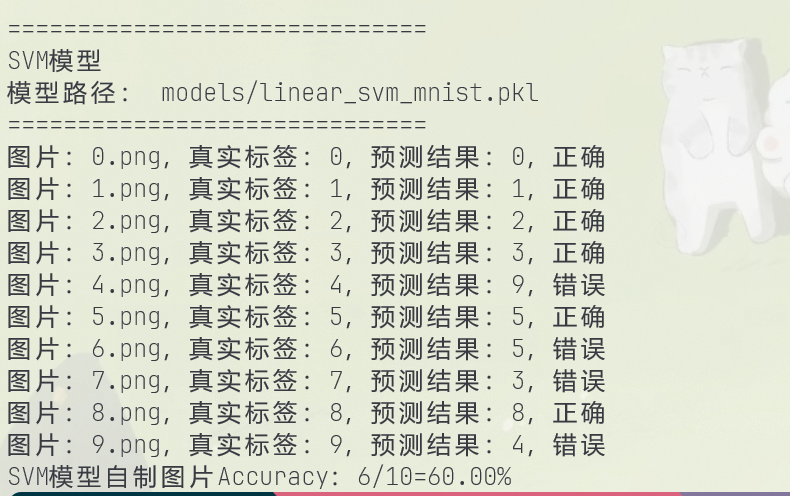
SVM预测结果(6/10 = 60%):
CNN预测结果(9/10 = 90%):

| 模型 | MNIST测试集 | 自制图片 |
|---|---|---|
| 逻辑回归 | 92.57% | 60.00% |
| SVM | 91.83% | 60.00% |
| CNN | 98.93% | 90.00% |
标准测试集分数高不代表真实场景就一定好用。数据预处理、书写风格、笔画粗细等因素都会严重影响实际效果。
关键问题与思考
1. 为什么 CNN 比逻辑回归和 SVM 强这么多?
逻辑回归和 SVM 需要把 28×28 图片”拍扁”成 784 个独立像素值,完全丢失了数字的笔画走向、边缘形状、局部结构等空间信息。CNN 通过卷积核扫描整张图片,能自动学到”横线””竖线””弯曲”等低级特征,再逐层组合成”圆圈””交叉”等高级模式,因此对手写数字的识别能力更强。
一句话总结:传统模型看的是像素点,CNN 看的是形状和结构。图像识别本质上需要的是”理解形状”的能力,而非”记住像素”。
2. 训练数据不足怎么办?
- 数据增强:旋转、平移、缩放、加噪声、改变笔画粗细
- 迁移学习:用预训练模型微调
- 收集更多真实数据
3. 图片底色和方向有影响吗?
有很大影响。MNIST 接近黑底白字,而实际拍照的图片往往是白底黑字。解决方法:训练阶段加入不同背景和角度的增强样本;预测阶段做灰度化、二值化、反色、倾斜校正等处理。
4. 如何从单数字识别升级到邮政编码识别?
这需要额外的处理步骤:先定位信封上的编码区域 → 图像去噪和校正 → 将连续数字分割成单个字符 → 逐字识别 → 组合结果。如果数字粘连严重,可以考虑用目标检测或 CRNN 序列识别模型。
总结
这次实验完整走通了机器学习项目的全流程:数据加载 → 预处理 → 模型构建 → 训练 → 评估 → 实际应用测试。几个核心收获:
模型选择很重要 — 传统模型(逻辑回归/SVM)在 MNIST 上也能取得不错的效果,但 CNN 更适合图像任务
测试集分数不是全部 — 91% 的测试准确率在自制图片上可能只剩 60%
数据预处理是核心竞争力 — 改进预处理方法后,识别效果有明显提升
多指标评估 — 不要只看 Accuracy,Precision、Recall、F1-Score 和混淆矩阵能提供更全面的视角
完整代码已开源,欢迎交流讨论。
本文基于个人实验整理,如有错误欢迎指正。