数据结构综合设计实验报告
本文为数据结构课程综合设计实验报告,涵盖三个独立实验,分别涉及线性表、二叉树、链表三大核心数据结构的综合应用。
实验一:学生成绩管理系统——排序与查找
问题描述
设计一个学生成绩管理系统,从 score.txt 文件中读入学生成绩数据并存储到线性表中,支持多算法排序和多维度查找。
本实验综合运用了文件操作、线性表存储、排序算法和查找算法四大核心知识点。
实验要求
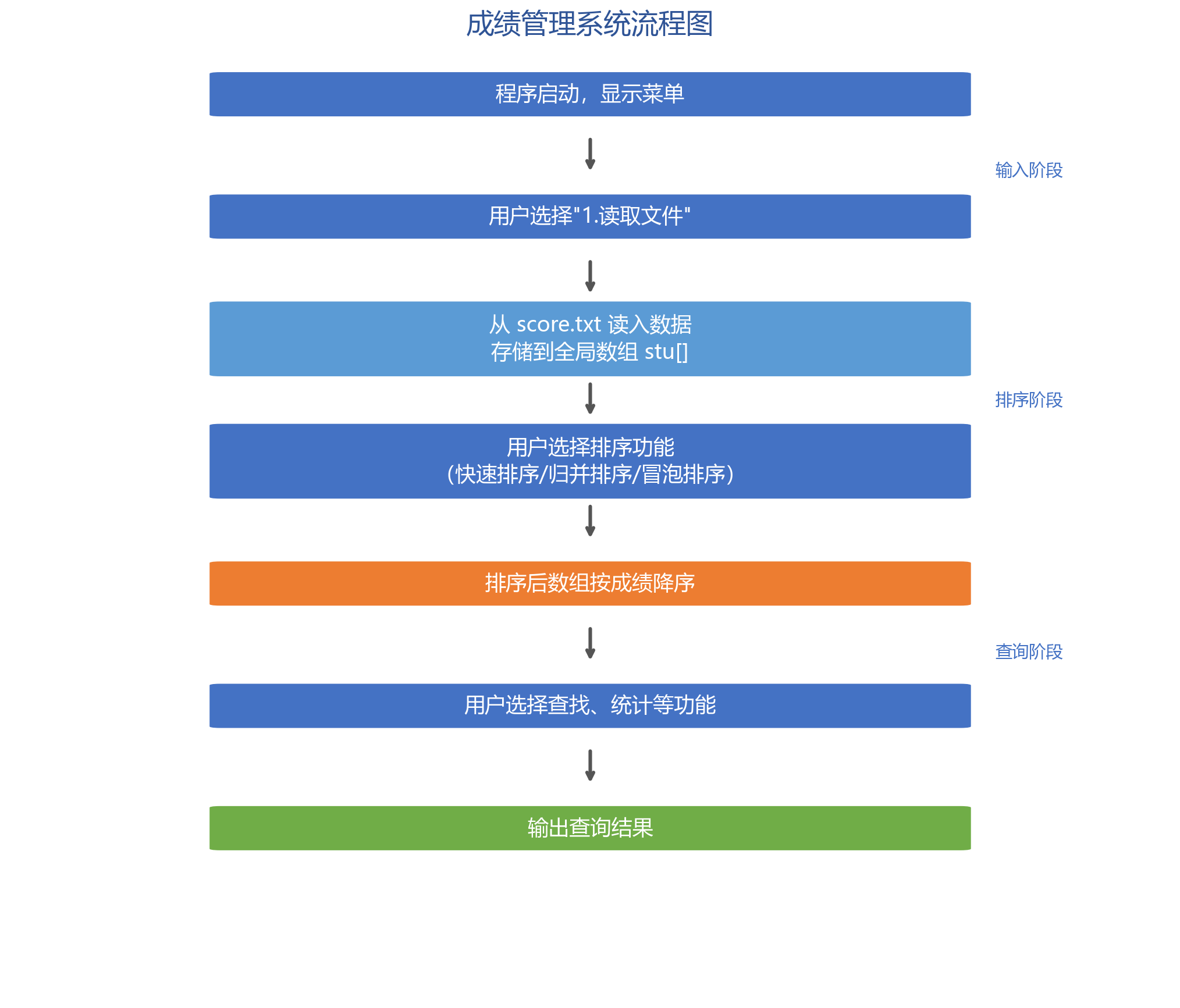
从 score.txt 读入学生成绩,存储到全局数组 stu[]
支持多种排序算法(快速排序 / 归并排序 / 冒泡排序)
排序后按成绩降序输出
支持按姓名/学号查找,支持最高分Top10统计
动态菜单交互
系统流程
数据结构
1 | typedef struct { |
三种排序算法
排序算法对比
| 算法 | 平均 | 最坏 | 空间 | 稳定性 |
|---|---|---|---|---|
| 快速排序 | O(n log n) | O(n²) | O(log n) | 不稳定 |
| 归并排序 | O(n log n) | O(n log n) | O(n) | 稳定 |
| 冒泡排序 | O(n²) | O(n²) | O(1) | 稳定 |
小结
文件读取与结构体数组管理
三种排序算法对比实现
顺序查找与二分查找的适用场景
实验二:长整数四则运算
问题描述
计算机内置类型有范围限制(long long 最大约 9×10¹⁸),超出此范围需自定义数据结构完成运算。
本实验的核心挑战在于进位/借位的链式传播以及任意精度的精确计算。
实验要求
任意长整数的加法、减法,乘除可选做
进位、借位正确处理
按中国习惯每四位一组分隔显示
数据结构:双向循环链表
1 | typedef struct Node { |
如 1,0000,0000,0000 表示为三个结点,分别存储 1、0、0。
核心算法
加法算法
- 对齐两个长整数结点(从低位向高位)
- 逐结点相加,处理进位
carry - 最高位若有进位则创建新结点
1 | LongInt* Add(LongInt *a, LongInt *b) { |
减法算法
1 | LongInt* Subtract(LongInt *a, LongInt *b) { |
测试结果
| 序号 | 输入 A | 输入 B | 运算 | 输出 |
|---|---|---|---|---|
| 1 | 0 | 0 | A+B | 0 |
| 2 | 2345,6789 | -7654,3211 | A+B | 1,0000,0000 |
| 3 | 1,0000,0000,0000 | 9999,9999 | A+B | 9999,0000,0001 |
| 4 | 1,0001,0001 | 1,0001,0001 | A-B | 0 |
边界处理
| 情况 | 处理 |
|---|---|
| 结果全零 | 去前导零,保留一个 0 |
| 符号不同 | 加法转减法,减法转加法 |
| 借位传播 | 持续向前借位 |
小结
双向循环链表构建与操作
任意长度整数加/减运算
进位、借位、符号等边界情况
实验三:哈夫曼编码/译码器
问题描述
利用哈夫曼编码进行信息通信可提高信道利用率。设某编码系统共有 n 个字符,使用频率分别为 {w1, w2, …, wn},设计不等长编码方案使空间效率最好。
核心思想:频率高的字符用短编码,频率低的用长编码,使加权路径长度最短。
实验要求
从终端读入字符集大小 n 及 n 个字符和权值,建立哈夫曼树
利用已建好的哈夫曼树对正文进行编码和译码
打印编码表和哈夫曼树结构
系统流程
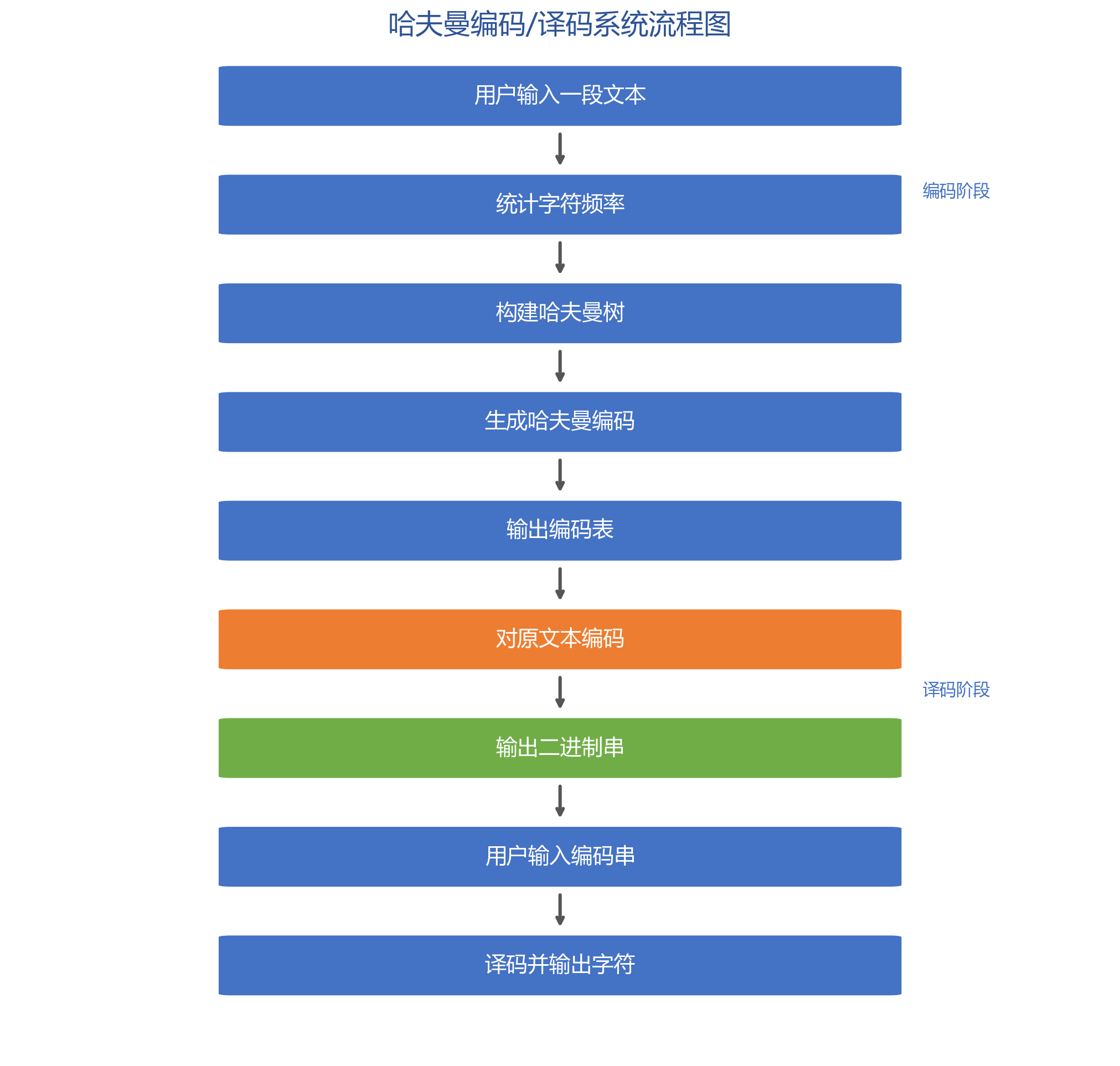
数据结构
1 | typedef struct { |
由于哈夫曼树共有 2n-1 个结点(n-1 次合并),数组长度为 2n-1。
核心算法
Select 函数
1 | void Select(HTNode HT[], int n, int *s1, int *s2) { |
编码生成
- 从叶子回溯到根:左孩子 → 编码
0,右孩子 → 编码1 - 将路径字符串逆序即为该字符的哈夫曼编码
译码
从根出发:读 0 走左孩子,读 1 走右孩子,到达叶子则输出字符并回到根。
模块划分
| 函数 | 功能 |
|---|---|
CountFrequency |
统计字符频率 |
CreateHuffmanTree |
构建哈夫曼树 |
CreateHuffmanCode |
生成编码表 |
Encode |
对原文编码 |
Decode |
对编码串译码 |
PrintCode |
打印编码对照表 |
运行结果
运行示例
1 | 请输入字符集大小: 6 |
小结
哈夫曼树构建(贪心策略)
前缀编码生成与译码
时间复杂度 O(n²),堆优化可降至 O(n log n)
总结对比
三个实验从不同角度诠释了数据结构的核心价值——用正确的结构存储数据,用高效的算法处理数据。无论是线性表的排序查找、链表的动态存储,还是二叉树的最优编码,都是计算机科学的基石。