Claude Code + DeepSeek V4 Pro + 千问VL:零成本为国产大模型装上"眼睛"
写在前面
这套方案已经在我自己的电脑上跑通了——截图发过去,AI 自动识别,全程无需手动敲命令。写这篇博客的截图就是用这套方案识别的。
一、背景:为什么需要”眼睛”?
国产大模型接入 Claude Code 之路
第一步:接入 DeepSeek
Claude Code 本身是 Anthropic 的产品,原生对接 Claude 系列模型。但通过自定义 API Base URL,我们可以接入任何兼容 OpenAI 格式的模型——包括国产的 DeepSeek V4 Pro。
这一步已经有很多教程了,配置之后,你在终端里拥有了一个强大的 AI 编程助手。
第二步:发现盲区
用着用着你会发现一个问题——截图发过去,AI 一脸懵。
DeepSeek V4 Pro 是纯文本模型,不具备视觉能力。当你把报错截图、设计稿、UI 对比图拖进去时,它只能看到文件路径,无法理解图片内容。
第三步:补上眼睛
我们需要一个”翻译官”——把图片发给有 vision 能力的模型,让它用文字描述回来。
阿里云百炼的千问 VL 模型恰好合适:便宜(新用户 100 万 Token 免费)、兼容 OpenAI 格式、中文理解力强。
二、方案原理
graph LR
A[用户发图片] --> B[Claude Code]
B --> C[CLAUDE.md 触发规则]
C --> D[vision.js 脚本]
D --> E[读取图片 → Base64]
E --> F[千问 VL 模型 API]
F --> G[返回文字描述]
G --> B
B --> H[DeepSeek V4 Pro 分析回复]
核心思路:图片不进 DeepSeek,而是绕道千问 VL 先转成文字,再把文字交给 DeepSeek 处理。 整个过程对用户透明——你只管发图,AI 自动处理。
三、完整配置步骤
步骤 1:获取千问 API Key
点击展开:阿里云百炼注册 & 获取 Key
- 打开 阿里云百炼控制台
- 登录阿里云账号(没有就先注册)
- 在控制台找到 API Key 管理,创建一个新 Key
- 复制生成的 Key(形如
sk-xxxxxxxxxxxxxxxx)
新用户赠送 100 万 Token 免费额度,有效期 90 天。日常看图每次消耗约 500-1000 Token,够用上千次。
步骤 2:克隆 vision.js 脚本
教程来源:GitHub 开源项目 asuojun/claude-vision-skill,感谢作者提供了一键式解决方案。
1 | git clone https://github.com/asuojun/claude-vision-skill.git D:/deepseek-vision |
步骤 3:配置 API Key 和模型
打开 D:/deepseek-vision/.env,填写:
1 | DASHSCOPE_API_KEY=你的真实Key |
vision.js 中的模型已预设为 qwen-vl-max(性价比最高的 VL 模型):
1 | const MODEL = process.env.VISION_MODEL || "qwen-vl-max"; |
为什么选 qwen-vl-max?
| qwen-vl-max | qwen3.5-omni-plus | |
|---|---|---|
| 输入 | 1.6 元/百万 Token | ~0.8 元/百万 Token |
| 输出 | 4 元/百万 Token | ~4.8 元/百万 Token |
| 定位 | 纯视觉理解 | 全模态(视觉+音频) |
| 推荐 | 日常看图首选 ✅ | 需要音频识别时用 |
qwen-vl-max 输出更便宜,日常识图场景完全够用。
步骤 4:配置 CLAUDE.md
在项目根目录创建或修改 CLAUDE.md,告诉 Claude Code 何时调用 vision.js:
1 | # 识图能力 |
步骤 5:测试
发一张截图给 Claude Code,它应该自动执行:
1 | node /d/deepseek-vision/vision.js "D:/截图专用/xxx.png" "用中文描述这张图片" |
我的测试结果示例
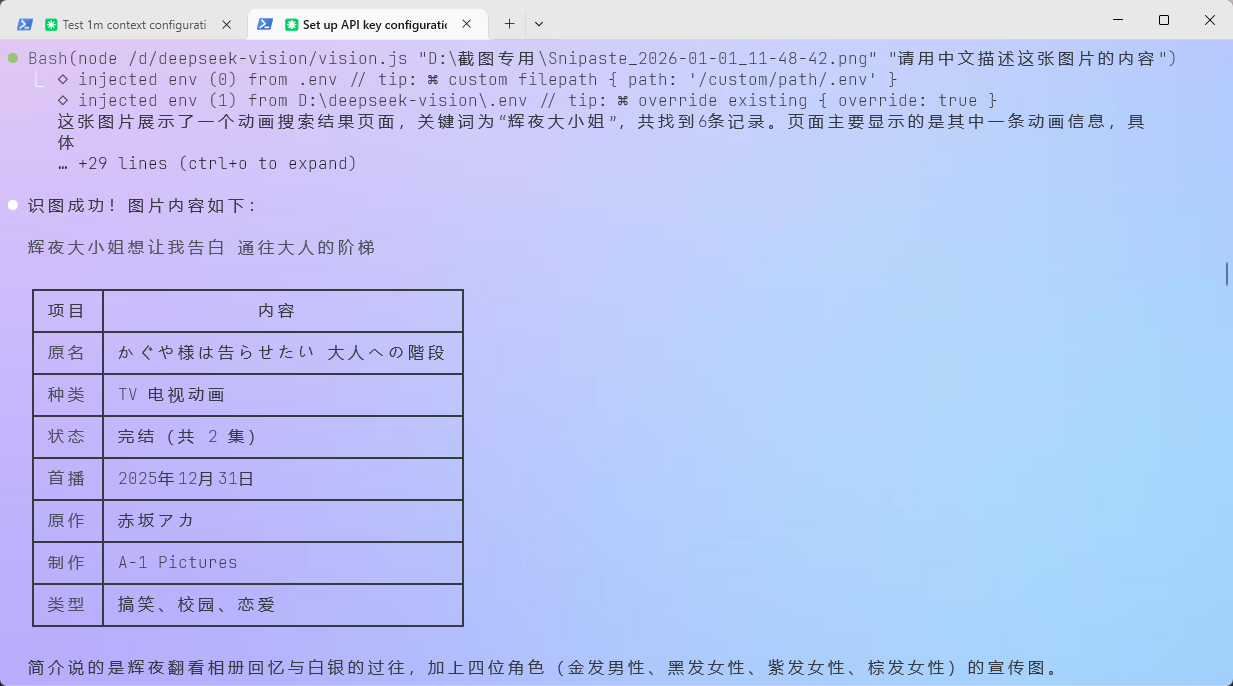
千问 VL 返回的描述:
这张图片展示了一个动画搜索结果页面,关键词为”辉夜大小姐”,共找到6条记录。动画名称:《辉夜大小姐想让我告白 通往大人的阶梯》,原名:かぐや様は告らせたい 大人への階段,动画种类:TV,播放状态:完结,首播时间:2025年12月31日,原作:赤坂アカ,制作公司:A-1 Pictures,剧情类型:搞笑、校园、恋爱……
识别准确,中文描述流畅,完全可用。
四、成本分析
| 方案 | 月费 | 识图能力 |
|---|---|---|
| 本方案:DeepSeek + 千问 VL | 0 元 | ✅ |
| Claude Pro 订阅 | $20/月 | ✅ 原生 |
| ChatGPT Plus | $20/月 | ✅ 原生 |
五、教程来源与参考链接
点击展开:所有参考来源
核心教程
asuojun/claude-vision-skill — 识图脚本开源仓库
本方案的核心 vision.js 脚本来自这个仓库。作者提供了完整的 CLI 配置指令,支持千问、OpenAI 及其他 OpenAI 兼容格式的 vision 模型。本文的配置步骤基于该仓库的 README 和 CLAUDE.md 指引。
DeepSeek 接入 Claude Code 教程
Claude Code 支持通过自定义 API Base URL 和 API Key 接入任何兼容 OpenAI 格式的模型。配置方式:
- 在 Claude Code 设置中修改 API 地址指向 DeepSeek 服务
- 或通过环境变量 / 配置文件指定 provider
具体的 DeepSeek API 接入参数可参考 DeepSeek 官方文档。
千问 VL 模型定价
六、常见问题
Q1: vision.js 报 Incorrect API key
原因:dotenv 包未安装,.env 文件未被读取。
解决:1
2cd D:/deepseek-vision
npm install dotenv
Q2: 图片路径有空格怎么处理?
用双引号包裹路径即可:1
node /d/deepseek-vision/vision.js "D:/我的 图片/test.png"
Q3: 网络图片能用吗?
支持。使用 --url 参数:1
node /d/deepseek-vision/vision.js --url "https://example.com/image.png"
Q4: 能不能换其他 vision 模型?
可以。修改 .env 中的 DASHSCOPE_API_KEY 和 vision.js 中的 BASE_URL 与 MODEL 即可,只要是 OpenAI 兼容格式的 vision API 都支持。
结语
创作说明:本文方案基于 asuojun/claude-vision-skill 开源项目。DeepSeek V4 Pro 接入 Claude Code 的配置方法参考社区教程。千问 VL 模型定价信息来源于阿里云百炼官方文档(2026年5月)。